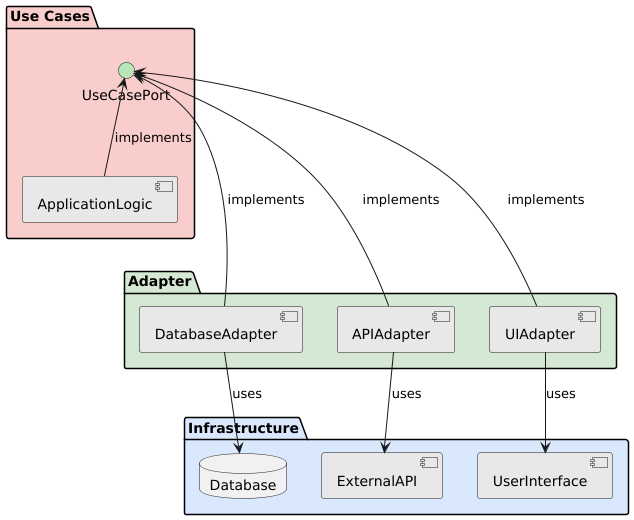
Das Adapter Pattern spielt eine zentrale Rolle in Clean Architecture, da es die saubere Trennung zwischen den Architekturschichten ermöglicht und die Dependency Rule durchsetzt.
Das Adapter Pattern in Clean Architecture
Funktion und Bedeutung
Der Adapter erfüllt in Clean Architecture mehrere wichtige Funktionen:
Übersetzung: Konvertiert Daten zwischen externen Formaten und Domain-Modellen
Entkopplung: Schützt die Domänenlogik vor externen Abhängigkeiten
Externe Schnittstelle: Payment Provider API (z.B. PayPal, Stripe)
Domain Model: Interne Zahlungsabwicklung
Adapter-Aufgaben:
Konvertierung der Zahlungsdaten in Provider-spezifische Formate
Übersetzung von Statusmeldungen
Fehlerbehandlung und Mapping
Architektonische Vorteile
Der Einsatz des Adapter Patterns bietet konkrete Vorteile:
Austauschbarkeit: Payment Provider können ohne Änderung der Geschäftslogik gewechselt werden
Testbarkeit: Geschäftslogik kann unabhängig von externen Systemen getestet werden
Wartbarkeit: Änderungen an externen Schnittstellen bleiben auf Adapter begrenzt
Skalierbarkeit: Neue Payment Provider können einfach integriert werden
Kontroll- und Datenflüsse im Adapter Pattern
Eingehender Fluss (Inbound Flow)
Der eingehende Fluss beschreibt den Weg von externen Anfragen zur Domain:
1. Externe Anfrage
HTTP-Request oder API-Aufruf erreicht den Controller
Enthält Daten im externen Format (z.B. JSON)
Kann Authentifizierung und andere HTTP-Header enthalten
2. Controller-Verarbeitung
Validiert grundlegende Request-Parameter
Extrahiert relevante Daten
Leitet Daten an den Adapter weiter
3. Adapter-Transformation
Konvertiert externe Daten in Domain-Objekte
Validiert fachliche Regeln
Mapped Fehlerzustände
4. Use-Case-Ausführung
Erhält valide Domain-Objekte
Führt Geschäftslogik aus
Arbeitet ausschließlich mit Domain-Modellen
Datentransformation
Die Datentransformation erfolgt in mehreren Stufen:
Eingehende Transformation:
External DTO → Internal DTO → Domain Object
Validierung auf jeder Ebene
Anreicherung mit Domain-Kontext
Ausgehende Transformation:
Domain Object → Internal DTO → External DTO
Filterung sensitiver Daten
Format-spezifische Anpassungen
Ausgehender Fluss (Outbound Flow)
Der ausgehende Fluss beschreibt den Weg von der Domain nach außen:
1. Domain-Ergebnis
Use-Case erzeugt Domain-Ereignis oder -Ergebnis
Enthält reine Domain-Objekte
Unabhängig von externen Formaten
2. Adapter-Transformation
Konvertiert Domain-Objekte in DTOs
Bereitet Daten für externe Darstellung auf
Handhabt spezifische Formatierungen
3. Presenter-Aufbereitung
Formatiert Daten für spezifische Ausgabekanäle
Fügt Präsentations-Metadaten hinzu
Handhabt Response-Formate
Fehlerbehandlung
Die Fehlerbehandlung erfolgt schichtspezifisch:
Domain-Ebene:
Business Rule Violations
Domain-spezifische Ausnahmen
Invarianten-Verletzungen
Adapter-Ebene:
Mapping von Domain-Fehlern auf externe Formate
Transformation technischer Fehler
Protokollierung und Monitoring
External-Ebene:
HTTP-Statuscodes
API-spezifische Fehlermeldungen
Client-freundliche Fehlerinformationen
Praktische Implementierungsaspekte
Mapping-Strategien:
Explizite Konvertierungsmethoden
Mapping-Frameworks für komplexe Transformationen
Immutable DTOs für Datensicherheit
Performance-Optimierung:
Lazy Loading wo sinnvoll
Caching von Transformationen
Bulk-Operationen für große Datenmengen
Best Practices
Interface Segregation: Spezifische Schnittstellen für verschiedene Anwendungsfälle
Single Responsibility: Jeder Adapter für genau einen externen Service
Dependency Inversion: Abhängigkeiten zeigen nach innen zur Domain
Explizite Konvertierung: Keine impliziten Typumwandlungen
Fazit
Das Adapter Pattern ist ein fundamentaler Baustein in Clean Architecture, der die praktische Umsetzung der Architekturprinzipien ermöglicht. Es schafft die notwendige Flexibilität für langlebige, wartbare Systeme bei gleichzeitiger Wahrung der architektonischen Integrität.
Moderne Softwareentwicklung für nachhaltige Systeme
Clean Architecture ist mehr als ein theoretisches Konzept – es ist der Schlüssel zu wartbarer, testbarer und zukunftssicherer Software. Erfahren Sie, wie wir Clean Architecture in der Praxis umsetzen und welche konkreten Vorteile sich daraus für Ihr Unternehmen ergeben.
Inhaltsübersicht
Grundprinzipien
Praktische Implementierung
Vorteile für Ihr Unternehmen
Best Practices aus realen Projekten
Häufige Herausforderungen und Lösungen
Grundprinzipien
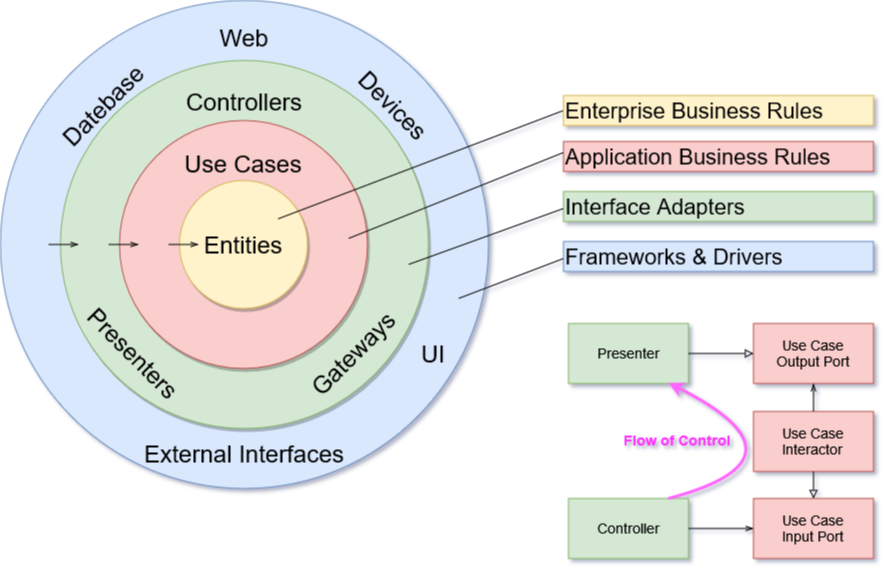
Clean Architecture, entwickelt von Robert C. Martin, ist ein Architekturmuster, das die nachhaltige Entwicklung komplexer Softwaresysteme ermöglicht. Die Kernprinzipien zielen darauf ab, Software zu schaffen, die leicht zu warten, zu testen und weiterzuentwickeln ist.
Die Dependency Rule
Das zentrale Prinzip der Clean Architecture ist die Dependency Rule: Abhängigkeiten in der Softwarearchitektur dürfen nur von außen nach innen zeigen. Die inneren Schichten dürfen nichts von den äußeren Schichten wissen.
Die konzentrischen Schichten der Clean Architecture
Die vier Schichten
Entities (Innerste Schicht): Enthält die Geschäftsregeln und Datenstrukturen des Unternehmens
Use Cases: Implementiert die Anwendungsfälle und Geschäftslogik
Interface Adapters: Konvertiert Daten zwischen Use Cases und externen Systemen
Frameworks & Drivers: Enthält Frameworks, Datenbanken und UI-Komponenten
SOLID-Prinzipien in der Clean Architecture
Clean Architecture basiert auf den SOLID-Prinzipien der objektorientierten Programmierung:
Single Responsibility: Jede Komponente hat genau eine Aufgabe
Open-Closed: Offen für Erweiterungen, geschlossen für Änderungen
Liskov Substitution: Austauschbarkeit von Implementierungen
Dependency Inversion: Abhängigkeiten von Abstraktionen
Vorteile der Schichtenarchitektur
Die strikte Trennung der Schichten bietet mehrere entscheidende Vorteile:
Unabhängigkeit von Frameworks und externen Tools
Einfache Testbarkeit durch klare Grenzen
Unabhängigkeit von der Benutzeroberfläche
Unabhängigkeit von der Datenbank
Unabhängigkeit von externen Systemen
Vorteile der Clean Architecture im Überblick
Die Rolle von Interfaces
Interfaces spielen eine zentrale Rolle in der Clean Architecture. Sie definieren die Grenzen zwischen den Schichten und ermöglichen die Dependency Inversion:
Definieren von Verträgen zwischen Schichten
Ermöglichen von Mock-Implementierungen für Tests
Vereinfachen den Austausch von Implementierungen
Fördern lose Kopplung zwischen Komponenten
Praktische Implementierung
Die praktische Umsetzung der Clean Architecture erfordert eine durchdachte Projektstruktur und klare Konventionen. In diesem Kapitel zeigen wir, wie die theoretischen Konzepte in der Praxis umgesetzt werden.
Projektstruktur
Eine typische Projektstruktur nach Clean Architecture-Prinzipien könnte wie folgt aussehen:
project/
├── domain/ # Entities und Business Rules
├── application/ # Use Cases
├── interfaces/ # Interface Adapters
└── infrastructure/ # Frameworks & Drivers
Domain Layer
Die Domain-Schicht enthält die Geschäftsobjekte und -regeln, völlig unabhängig von äußeren Schichten. Sie bildet das Herzstück jeder Anwendung und repräsentiert die wertvollsten Geschäftsregeln des Unternehmens. Diese unveränderlichen Geschäftsregeln (Invarianten) werden im Rich Domain Model implementiert, das weit mehr als nur Datenstrukturen enthält.
Geschäftsregeln als Code:
Validierungslogik direkt in den Entities
Geschäftsprozesse als Domain Services
Invarianten werden aktiv durchgesetzt
Selbstvalidierung der Geschäftsobjekte
Domänenspezifische Sprache:
Ubiquitous Language aus dem Domain-Driven Design
Geschäftsbegriffe direkt im Code abgebildet
Klare Kommunikation zwischen Fachbereich und Entwicklung
Use Cases
Die Anwendungsschicht implementiert die Geschäftslogik und orchestriert den Datenfluss:
Typischer Datenfluss in einem Use Case
Interface Adapters
Die Adapter-Schicht konvertiert Daten zwischen dem Format der Use Cases und externen Formaten:
Dependency Injection ist ein Schlüsselmechanismus für die Umsetzung der Dependency Rule.
Praktische Beispiele für Grenzüberschreitungen
Die Kommunikation zwischen den Schichten erfolgt über definierte Boundaries:
Korrekte Implementierung von Boundary Crossings
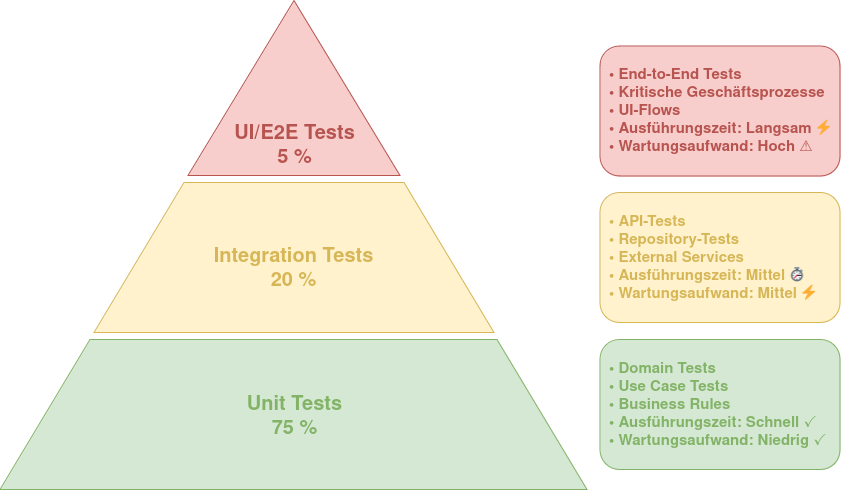
Testing-Strategien
Clean Architecture ermöglicht effektives Testing auf allen Ebenen:
Unit Tests für Entities und Use Cases
Integration Tests für Adapter
End-to-End Tests für komplette Flows
Mocking von externen Abhängigkeiten
Häufige Herausforderungen und Lösungen
Performance-Overhead: Strategien zur Optimierung
Komplexität: Richtlinien zur Vereinfachung
Team-Onboarding: Dokumentation und Standards
Legacy-Integration: Schrittweise Migration
Vorteile im Unternehmen
Clean Architecture ist mehr als ein technisches Konzept – sie bietet handfeste wirtschaftliche Vorteile für jedes Unternehmen. In diesem Kapitel zeigen wir, wie sich die Implementierung von Clean Architecture auf Ihre Geschäftsziele auswirkt.
Kosteneinsparungen durch verbesserte Wartbarkeit
Die strukturierte Architektur führt zu messbaren Kosteneinsparungen:
Reduzierung der Wartungskosten um bis zu 40%
Schnellere Fehlerbehebung durch isolierte Komponenten
Geringerer Aufwand bei der Einarbeitung neuer Entwickler
Minimierung technischer Schulden
Wartungskosten: Traditionelle vs. Clean Architecture
Geschäftsrisiken werden durch verschiedene Faktoren minimiert:
Risiko
Clean Architecture Lösung
Technologie-Obsoleszenz
Einfacher Austausch von Frameworks
Vendor Lock-in
Unabhängigkeit von externen Systemen
Qualitätsprobleme
Verbesserte Testbarkeit
Entwickler-Fluktuation
Klare Struktur und Dokumentation
Skalierbarkeit und Zukunftssicherheit
Investitionsschutz durch zukunftssichere Architektur:
Einfache Skalierung bei wachsenden Anforderungen
Flexibilität bei technologischen Veränderungen
Problemlose Integration neuer Technologien
Anpassungsfähigkeit an veränderte Geschäftsanforderungen
ROI-Betrachtung
Der Return on Investment zeigt sich in verschiedenen Bereichen:
Kurzfristig:
Verbesserte Entwicklungseffizienz
Reduzierte Fehlerquoten
Mittelfristig:
Geringere Wartungskosten
Schnellere Feature-Entwicklung
Langfristig:
Reduzierte Gesamtbetriebskosten
Höhere Systemlebensdauer
Wettbewerbsvorteile
Clean Architecture verschafft Ihrem Unternehmen strategische Vorteile:
Schnellere Reaktion auf Marktveränderungen
Höhere Qualität Ihrer Softwareprodukte
Bessere Kundenservice durch stabile Systeme
Innovationsfähigkeit durch flexible Architektur
Best Practices aus realen Projekten
Die erfolgreiche Implementierung von Clean Architecture basiert auf praktischer Erfahrung. Hier teilen wir die wichtigsten Erkenntnisse aus zahlreichen Projekten.
Erfolgreiche Projekteinführung
Schrittweise Migration:
Identifikation kritischer Komponenten
Priorisierung nach Business-Impact
Inkrementelle Umstellung
Parallelbetrieb während der Migration
Architektur-Guidelines
Bewährte Richtlinien aus der Praxis:
Modulare Boundaries:
Klare Schnittstellendefinition
Explizite Abhängigkeiten
Versioning von Schnittstellen
Datenfluss:
Unidirektionaler Datenfluss
Immutable Data Transfer Objects
Klare Trennung von Kommandos und Abfragen
Häufige Fallstricke und Lösungen
Fallstrick
Lösung
Präventive Maßnahmen
Übermäßige Abstraktion
YAGNI-Prinzip anwenden
Regelmäßige Architektur-Reviews
Vermischung der Schichten
Strikte Dependency Rules
Automatisierte Architektur-Tests
Performanceprobleme
Gezielte Optimierung
Frühzeitiges Performance-Testing
Überengineering
Pragmatische Entscheidungen
Regelmäßige Refactoring-Zyklen
Team-Organisation und Entwicklungsprozess
Team-Struktur:
Feature-Teams statt Schichten-Teams
Klare Verantwortlichkeiten
Regelmäßige Architektur-Reviews
Entwicklungsprozess:
Continuous Integration
Automatisierte Tests
Regelmäßige Refactoring-Zyklen
Dokumentation und Wissenstransfer
Erfolgreiche Projekte zeichnen sich durch effektive Dokumentation aus:
Architektur-Entscheidungen (ADRs)
Boundary-Dokumentation
Onboarding-Guides
Living Documentation
Monitoring und Maintenance
Bewährte Praktiken für den Betrieb:
Monitoring:
Performance-Metriken pro Schicht
Dependency-Tracking
Error-Tracking über Schichtgrenzen
Maintenance:
Regelmäßige Dependency-Updates
Proaktives Refactoring
Technische Schulden-Management
Erfolgsfaktoren
Kritische Erfolgsfaktoren in der Praxis
Herausforderungen und Lösungen
Die Implementierung von Clean Architecture bringt spezifische Herausforderungen mit sich. Hier zeigen wir, wie Sie diese erfolgreich meistern können.
Performance-Optimierung
Eine häufige Sorge ist der vermeintliche Performance-Overhead durch die zusätzlichen Abstraktionsebenen.
Herausforderung
Lösung
Resultat
Mapping-Overhead
Caching-Strategien, Lazy Loading
Minimale Latenz
Datenbankzugriffe
Optimierte Repositories, Query-Optimierung
Effiziente Datenzugriffe
Memory-Nutzung
Object Pooling, Stream Processing
Optimierte Ressourcennutzung
Legacy-System-Integration
Die Integration bestehender Systeme erfordert eine durchdachte Strategie:
Strangler Fig Pattern:
Schrittweise Umstellung
Parallelbetrieb alter und neuer Komponenten
Gradueller Funktionsübergang
Anti-Corruption Layer:
Schutz der neuen Architektur
Übersetzung zwischen Systemen
Isolation von Legacy-Code
Strategien zur Legacy-Integration
Team-Skalierung
Herausforderungen bei wachsenden Teams:
Wissenstransfer:
Architektur-Workshops
Pair Programming
Dokumentations-Wikis
Koordination:
Feature Teams
Architektur-Guild
Code-Review-Prozesse
Technische Schulden Management
Strategien zur Vermeidung und Behebung technischer Schulden:
Regelmäßige Architektur-Reviews
Refactoring-Budgets
Automatisierte Architektur-Tests
Continuous Refactoring
Microservices-Integration
Clean Architecture in einer Microservices-Umgebung:
Die genannten Herausforderungen sind lösbar durch:
Klare Strategien und Richtlinien
Kontinuierliche Verbesserung
Pragmatische Entscheidungen
Fokus auf Business-Value
Softwarearchitektur ist vielschichtig und hilft bei der Beherrschung von wachsenden Softwaresystemen. RYPOX ist ein zuverlässiger Partner bei dieser Aufgabe.
Understanding Architectural Styles in Web Services
When it comes to designing network-based applications, two common architectural styles often come up for consideration: REST (Representational State Transfer) and SOAP (Simple Object Access Protocol). Both are used for exchanging data over the internet and for integrating systems, but they have fundamental differences in approach, capabilities, and usage scenarios.
Definition and Approach
REST is an architectural style that uses existing web standards and protocols, primarily HTTP. It is not a protocol or a standard itself but a set of principles (like statelessness and cacheability) that guide how the web should be used for building web services. REST is centered around resources and the manipulation of these resources.
SOAP, on the other hand, is a protocol defined with strict rules and advanced security features built into it. It uses XML for messaging and can be transported using various protocols such as HTTP, SMTP, TCP, and more. SOAP is not tied to any specific architectural style but is commonly associated with Service-Oriented Architecture (SOA).
Use of Standards
REST typically uses HTTP standard methods (GET, POST, PUT, DELETE) as the means for communication and interaction with data. This simplicity makes REST an easy-to-understand and implement approach. RESTful services often communicate using either JSON, XML or other lightweight formats.
SOAP strictly adheres to its own set of standards and requires the use of XML for messaging. The SOAP messages are much more structured and must include a specific envelope, header, and body. This can make SOAP messages heavier and more verbose.
Flexibility vs. Standardization
REST provides substantial flexibility in terms of data formats, transport methods, and architecture. This can be advantageous when quick development and integration with various systems and technologies are needed.
On the contrary, SOAP provides a much higher degree of standardization with built-in protocols for a wide variety of features such as security (WS-Security), transaction (WS-Coordination), and messaging (WS-Reliable Messaging). While this can make SOAP more complex and heavier, it is also more feature-rich out of the box, making it suitable for enterprise-level applications where robustness and compliance are critical.
Security
REST relies on underlying protocols for security and does not have its own security features. It typically uses HTTPS for secure communication but depends on external methods for other security needs like token-based authentication, OAuth, etc.
SOAP has comprehensive security features built into its framework with standards like WS-Security that provide full encryption and built-in authentication, making it highly secure and suitable for scenarios where security is a significant concern, such as financial services.
Performance and Speed
Due to the lightweight nature of REST, it generally performs better and is faster than SOAP. REST is stateless, and it can be cached to improve performance and scalability. The verbose XML format of SOAP, required envelopes, and detailed processing model can lead to slower processing and larger message sizes.
Suitability
REST is particularly well-suited for internet-based applications where bandwidth and resources are limited, and simple CRUD (Create, Read, Update, Delete) operations are predominantly used. It’s chosen for mobile apps, IoT devices, and services meant for web consumption.
SOAP, with its strict standards and robust feature set, is generally chosen for enterprise-level applications which require high levels of transactional reliability, security, and formal contracts between client and server like in financial services, telecommunications, and critical business processes.
Conclusion
Choosing between REST and SOAP depends heavily on the specific needs and constraints of your project. If you need a lightweight, flexible approach that easily integrates with web technologies, REST is your go-to. However, if your application demands strict reliability, security, and standardization, SOAP might be the more suitable option.
In summary, understanding these two approaches helps in making informed decisions that align with your project’s requirements, ensuring both functional and strategic fit while designing your network-based applications.
Components of RESTful systems play a crucial role in making web communications effective and organized. Understanding these can help you grasp how data moves around in applications like when you’re shopping online or checking social media.
1. Resources
At the heart of any RESTful service are resources. A resource can be anything that can be described and is important to the web service you’re interacting with. For examples:
In a social media app, resources could be user profiles, photos, or posts.
In an online bookstore, resources might be books, authors, or book reviews.
Resources are identified by URIs (Uniform Resource Identifiers), which are basically web addresses (like https://example.com/profiles/john-doe). This URI directly points to the resource you want to access or manipulate.
2. URIs (Uniform Resource Identifiers)
A URI is a specific character string that uniquely identifies a resource. To adhere to RESTful principles, URIs should be designed to be easy for users to predict and understand. For instance:
Bad URI example: https://example.com/index.php?type=profile&id=57
Good URI example: https://example.com/profiles/57
The good example clearly tells you that you are likely getting information related to a profile with an ID of 57. It’s straightforward and user-friendly.
3. Methods
REST uses several standard HTTP methods that define what actions you might want to perform on a resource. We briefly touched on these in the introduction, but here they are again with a bit more detail:
GET: Retrieve information about a resource without changing it. For example, getting a list of blog posts.
POST: Used to create a new resource. For example, posting a new comment.
PUT: Update an existing resource. For example, editing your profile information.
PATCH: Partial update of resource. For example, changing one attribute.
DELETE: Remove an existing resource. For example, deleting an old photo.
Each of these operations plays a critical role in manipulating the resources on the server according to the client’s needs.
4. Representations
When a client makes a request to a server, it is not always obvious how the server will send back that data. REST uses representations to handle this communication. A representation is essentially a format in which resource data is structured when it is exchanged between client and server. Common representation formats include:
JSON (JavaScript Object Notation): Lightweight and easy for humans to read and write, and easy for machines to parse and generate.
XML (eXtensible Markup Language): A more verbose format, used less commonly in new APIs but still prevalent in many legacy systems.
Here’s an example of what a representation might look like using JSON:
By understanding and using these core components, developers can create more efficient and effective web services. They help in maintaining a standard structure and predictability across different systems, easing the process of integration and scalability.
In today’s digital world, communicating over the internet has become commonplace, not just among people but also between software programs. When you use apps like Facebook, Instagram, or when you check the weather on your phone, you are unknowingly interacting with web services. One popular way these apps interact with each other is through something called REST, which stands for Representational State Transfer. Let’s dive into what REST is and why it’s so important.
What is REST?
REST is a set of rules or guidelines that developers follow when they create web applications that other programs can talk to (like how your weather app talks to a server to get the latest weather updates). It’s not a programming language, software, or tool; it’s more like a set of standards everyone agrees on to ensure smooth communication over the internet.
How Does REST Work?
Imagine you’re ordering food from a restaurant via an app on your phone. In this scenario:
You are the client – You’re asking for something.
The app is the interface – It takes your order and shows you what’s available.
The restaurant’s server is the server – It has all the info and fulfills your request.
When you order, say, a pizza, the app sends that request to the restaurant’s server. The server checks if it can make a pizza, prepares it, and tells the app it’s ready and how long it will take. This interaction follows REST principles when done over the internet.
Key Features of REST
Resource Identification Through URI: In REST, everything is a resource – a piece of information or an object (like a weather report or a Facebook profile). These resources are identified and accessed through URIs (Uniform Resource Identifiers), which are simply web addresses.
Stateless Interactions: Each request from the client to the server must contain all the information the server needs to understand and fulfill the request. The server should not need to remember previous interactions to complete the current task.
Use of Standard HTTP Methods: REST uses standard HTTP methods like GET, POST, PUT, and DELETE, which are commands you can give to a server. For example, using GET to fetch data from the server, or POST to send data to the server.
GET: Retrieve information (like getting the menu from a restaurant).
POST: Create something new (like placing a new order).
PUT: Update something that already exists (like changing your order).
PATCH: Partial update with a small set of attributes.
DELETE: Remove something (like canceling an order).
Representations: When a client requests a resource using REST, the server responds with the data in a standard format that both understand, such as JSON or XML. This way, both the client and the server know how to interpret the information.
Why Use REST?
REST is popular because it’s simple, lightweight, and it works well over the internet. It uses web’s existing protocols and systems, requiring no additional software, libraries, or APIs, making it easy for developers to use and understand.
Moreover, since REST is based on standard practices and internet protocols, it is highly scalable and can handle a large number of requests efficiently.